Valley-free routing is a concept that may not be well known but that is relevant to datacenter design. In this post, we’ll valley-free routing based on a leaf and spine topology.
There are many posts about leaf and spine topology and the benefits. To summarize, some of the most prominent advantages are:
- Predictable number of hops between any two nodes.
- All links are available for usage providing high amount of bisection bandwidth (ECMP).
- The architecture is easy to scale out.
- Redundant and resilient.
Now, what does this have to do with valley-free routing? To understand what valley-free routing is, first let’s take a look at the expected traffic flow in a leaf and spine topology:
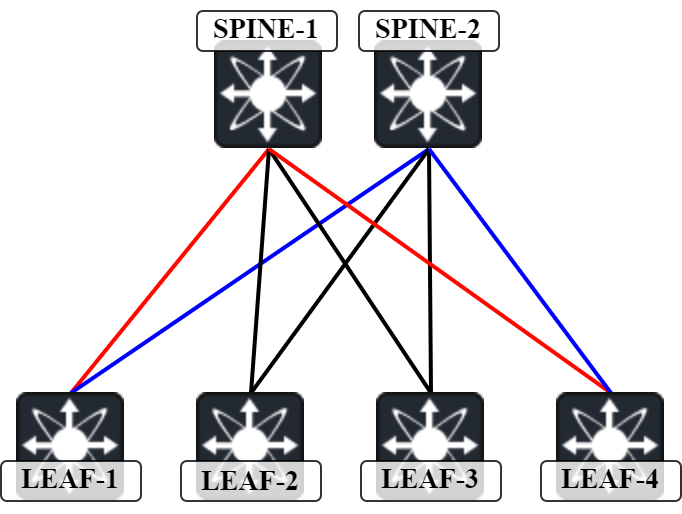
For traffic between Leaf1 and Leaf4, the two expected paths are:
- Red path – Leaf-1 to Spine-1 to Leaf-4.
- Blue path – Leaf-1 to Spine-2 to Leaf-4.
This means that there is only one intermediate hop between Leaf1 and Leaf4. Let’s confirm with a traceroute:
Leaf1# traceroute 203.0.113.4 traceroute to 203.0.113.4 (203.0.113.4), 30 hops max, 48 byte packets 1 Spine2 (192.0.2.2) 1.831 ms 1.234 ms 1.12 ms 2 Leaf4 (203.0.113.4) 2.613 ms 2.189 ms 2.095 ms
Currently the blue path is being used. In the stable topology there is valley-free routing. What is valley routing then? In this topology, think of the leaf switches as the valley. Valley routing is when traffic does not traverse only the spine to reach another leaf but rather takes a detour via a leaf to get there. This is shown below:
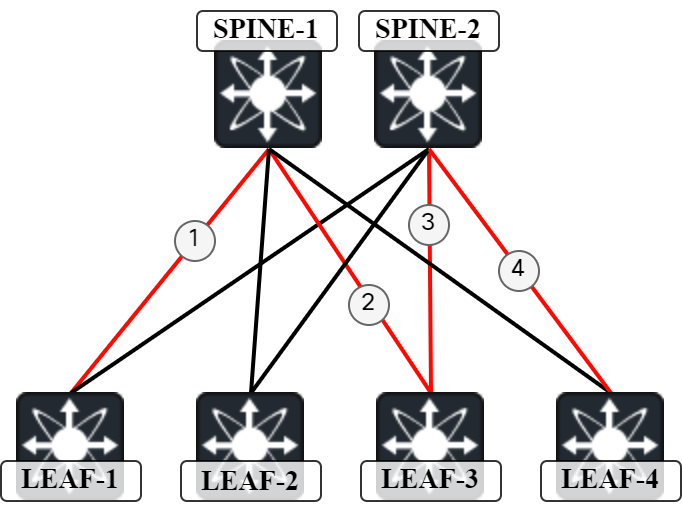
Traffic is flowing Leaf-1 to Spine-1 to Leaf-3 to Spine-2 and finally Leaf-4. Why would ever a path like this exist? This happens in this type of topology when there are multiple links down as can be seen below:
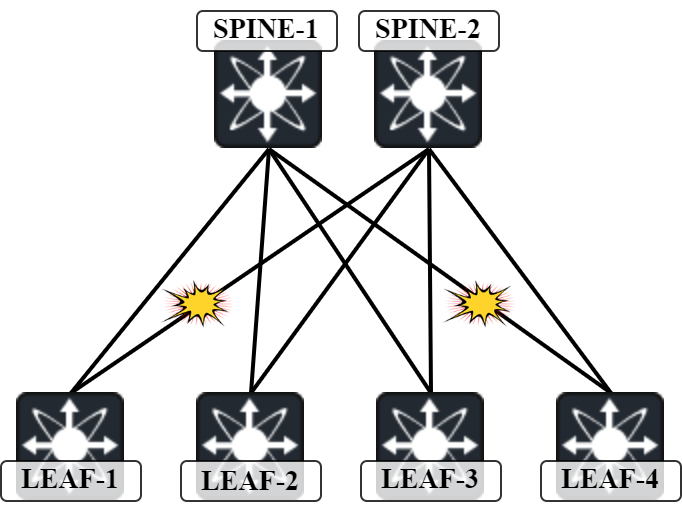
This type of event should be relatively rare but it can happen. Is there anything we can do about it? Increasing the number of spines would decrease the risk of there being no one-hop path between two leafs in the topology.
My lab is currently running OSPF in the underlay. Let’s shut down the link between Leaf-1 to Spine-2 and the link between Spine-1 to Leaf-4:
Leaf1(config)# int eth1/2 Leaf1(config-if)# shut Spine1(config)# int eth1/4 Spine1(config-if)# shut
Now let’s perform a traceroute on Leaf-1:
Leaf1# traceroute 203.0.113.4 traceroute to 203.0.113.4 (203.0.113.4), 30 hops max, 48 byte packets 1 Spine1 (192.0.2.1) 1.8 ms 1.092 ms 1.11 ms 2 Leaf3 (192.0.2.5) 2.482 ms 7.318 ms 6.583 ms 3 Spine2 (192.0.2.2) 6.548 ms 5.752 ms 4.743 ms 4 Leaf4 (203.0.113.4) 7.489 ms 4.484 ms 3.908 ms
Traffic is now traversing via Leaf-3 to get to Leaf-4. Why does OSPF not provide valley-free routing? OSPF is a link state topology where every router knows how all of the routers are connected within the area. For example, on Leaf-1 let’s take a look a Spine-1’s router LSA:
Leaf1# sh ip ospf data router 192.0.2.1 detail
OSPF Router with ID (192.0.2.3) (Process ID UNDERLAY VRF default)
Router Link States (Area 0.0.0.0)
LS age: 239
Options: 0x2 (No TOS-capability, No DC)
LS Type: Router Links
Link State ID: 192.0.2.1
Advertising Router: Spine1
LS Seq Number: 0x80000340
Checksum: 0x3f6e
Length: 108
Number of links: 7
Link connected to: a Stub Network
(Link ID) Network/Subnet Number: 192.0.2.1
(Link Data) Network Mask: 255.255.255.255
Number of TOS metrics: 0
TOS 0 Metric: 1
Link connected to: a Router (point-to-point)
(Link ID) Neighboring Router ID: 192.0.2.3
(Link Data) Router Interface address: 0.0.0.2
Number of TOS metrics: 0
TOS 0 Metric: 40
Link connected to: a Router (point-to-point)
(Link ID) Neighboring Router ID: 192.0.2.4
(Link Data) Router Interface address: 0.0.0.3
Number of TOS metrics: 0
TOS 0 Metric: 40
Link connected to: a Router (point-to-point)
(Link ID) Neighboring Router ID: 192.0.2.5
(Link Data) Router Interface address: 0.0.0.4
Number of TOS metrics: 0
TOS 0 Metric: 40
Link connected to: a Router (point-to-point)
(Link ID) Neighboring Router ID: 192.0.2.6
(Link Data) Router Interface address: 0.0.0.5
Number of TOS metrics: 0
TOS 0 Metric: 40
Link connected to: a Stub Network
(Link ID) Network/Subnet Number: 192.0.2.255
(Link Data) Network Mask: 255.255.255.255
Number of TOS metrics: 0
TOS 0 Metric: 1
As can be seen in the LSA, Leaf-1 is aware of what other routers Spine-1 is connected to. This means that in failure scenarios like these, OSPF will find alternate paths even if it means transiting through a leaf. Valley routing gives us more resiliency. Why would this be bad?
- The path is longer.
- Latency is not predictable.
- The path is not predictable.
- Link utilization is not predictable.
This may not sound so bad and might not be depending on application flows but it makes things difficult to predict. For example, let’s say Leaf-3 is already utilizing its uplinks at 50% Now there is an elephant flow from Leaf-1 to Leaf-4 that requires 60% of the capacity of Leaf-3’s uplinks. Now we have a problem and contention for bandwidth. This is why in design it is often better to fail predictably than to provide alternate solution which is not predictable. That is why many datacenters strive for valley-free routing. Not all, though.
Is BGP any different than OSPF when it comes to valley-free routing? As we know, OSPF is a link state protocol and BGP is a path vector protocol. This means BGP has no concept of topology, but that does not mean that there can never exist valley routing in BGP. It comes down to your ASN design and allocation. If using same AS for spines and unique AS for leafs, then there is valley-free routing. Such ASN design is shown below:
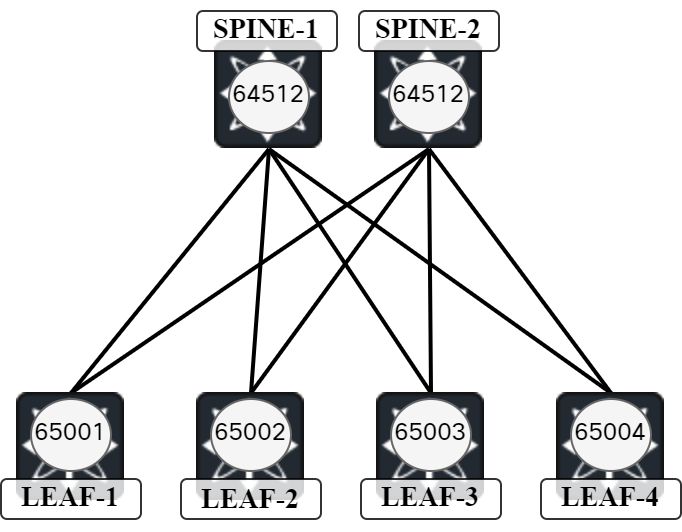
When topology is stable, Leaf-1 sees two paths to Leaf-4:
Leaf1# show bgp ipv4 uni
BGP routing table information for VRF default, address family IPv4 Unicast
BGP table version is 19, Local Router ID is 192.0.2.3
Status: s-suppressed, x-deleted, S-stale, d-dampened, h-history, *-valid, >-best
Path type: i-internal, e-external, c-confed, l-local, a-aggregate, r-redist, I-injected
Origin codes: i - IGP, e - EGP, ? - incomplete, | - multipath, & - backup, 2 - best2
Network Next Hop Metric LocPrf Weight Path
*>l203.0.113.1/32 0.0.0.0 100 32768 i
*|e203.0.113.2/32 198.51.100.8 0 64512 65002 i
*>e 198.51.100.0 0 64512 65002 i
*|e203.0.113.3/32 198.51.100.8 0 64512 65003 i
*>e 198.51.100.0 0 64512 65003 i
*|e203.0.113.4/32 198.51.100.8 0 64512 65004 i
*>e 198.51.100.0 0 64512 65004 i
Leaf1# show ip route 203.0.113.4/32
IP Route Table for VRF "default"
'*' denotes best ucast next-hop
'**' denotes best mcast next-hop
'[x/y]' denotes [preference/metric]
'%<string>' in via output denotes VRF <string>
203.0.113.4/32, ubest/mbest: 2/0
*via 198.51.100.0, [20/0], 00:15:28, bgp-65001, external, tag 64512
*via 198.51.100.8, [20/0], 00:00:32, bgp-65001, external, tag 64512
At this point I wanted to show how the spines drop BGP updates from leafs that contain their own AS, such as Leaf-3 advertising a prefix that belongs to Leaf-1 learned via Spine-2. As it turns out, NX-OS does not by default advertise prefixes in BGP containing AS of its peer in the AS path:

After configuring disable-peer-as-check on Leaf-3, we can see that Leaf-3 is now advertising the prefix to Spine-1 and it’s dropping it due to seeing its own AS in the AS path:
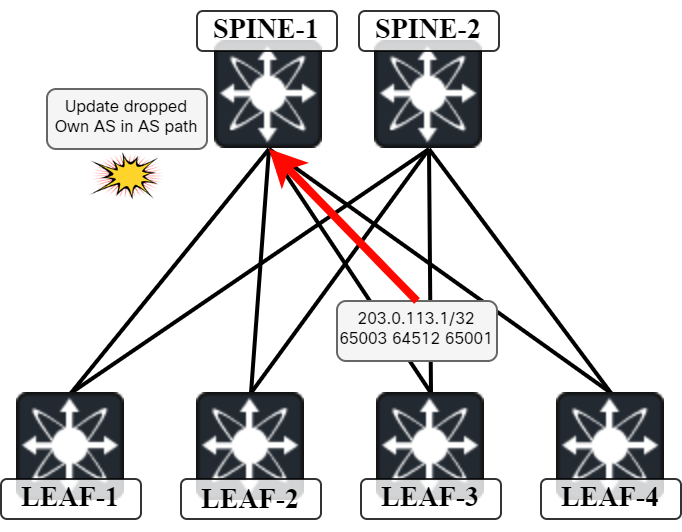
(default) UPD: 198.51.100.5 parsed UPDATE message from peer, len 62 , withdraw len 0, attr len 39, nlri len 0 (default) UPD: Attr code 1, length 1, Origin: IGP (default) UPD: Peer 198.51.100.5 nexthop length in MP reach: 4 (default) UPD: Recvd NEXTHOP 198.51.100.5 (default) UPD: Attr code 14, length 14, Mp-reach (default) UPD: 198.51.100.5 Received attr code 2, length 14, AS-Path: <65003 64512 65001 > (default) UPD: Received AS-Path attr with own ASN from 198.51.100.5 (default) UPD: [IPv4 Unicast] Received prefix 203.0.113.1/32 from peer 198.51.100.5, origin 0, next hop 198.51.100.5, localpref 0, med 0 (default) PFX: [IPv4 Unicast] Dropping prefix 203.0.113.1/32 from peer 198.51.100.5, due to attribute error (default) BRIB: [IPv4 Unicast] Unable to find path for dest 203.0.113.1/32 from peer 198.51.100.5, path_id: 0
203.0.113.1/32 is the loopback of Leaf-1.
We currently have valley-free routing. What happens if we create the same failure scenario as when running OSPF by disabling link from Leaf-1 to Spine-2 and link from Spine-1 to Leaf-4? Leaf-1 now has no route to Leaf-4:
Leaf1# show bgp ipv4 uni 203.0.113.4/32 Leaf1# show ip route 203.0.113.4/32 IP Route Table for VRF "default" '*' denotes best ucast next-hop '**' denotes best mcast next-hop '[x/y]' denotes [preference/metric] '%<string>' in via output denotes VRF <string> Route not found
This is valley-free routing! This is the expected and desired behavior. What if we wanted valley routing? Then spines need to use different AS as shown below:
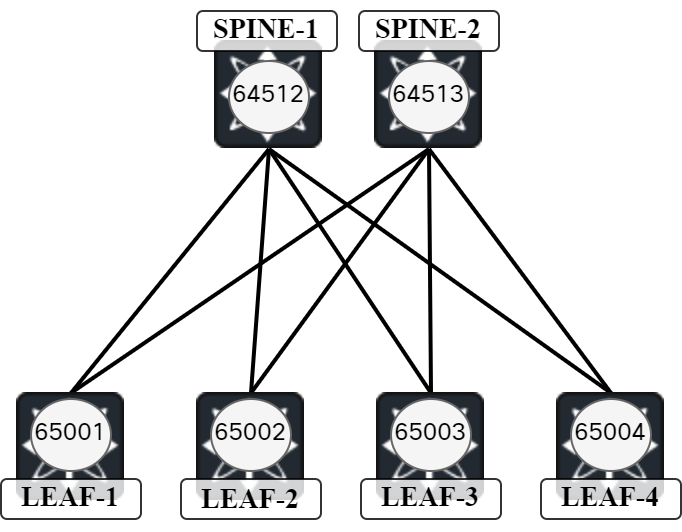
If we reconfigure the lab and leave the same links shutdown, Leaf-1 will have the following path towards Leaf-4:
Leaf1# sh bgp ipv4 uni | i 113.4 *>e203.0.113.4/32 198.51.100.0 0 64512 65002 64513 65004 i
The path is Leaf-1 to Spine-1 to Leaf-2 to Spine-2 to Leaf-4. Note that there is a single path only as BGP only advertises its best path only unless using a feature such as add path. Let’s confirm reachability with a traceroute:
Leaf1# traceroute 203.0.113.4 source-interface lo1 traceroute to 203.0.113.4 (203.0.113.4) from 203.0.113.1 (203.0.113.1), 30 hops max, 48 byte packets 1 Spine-1 (198.51.100.0) 1.815 ms 1.051 ms 1.009 ms 2 Leaf-2 (198.51.100.3) 2.711 ms 2.067 ms 1.961 ms 3 Spine-2 (198.51.100.10) 3.466 ms 3.386 ms 3.009 ms 4 Leaf4 (203.0.113.4) (AS 65004) 7.189 ms 4.339 ms 3.95 ms
This is valley routing! It all comes down to the ASN design. What have we learned in this post?
- The concept of valley-free routing.
- Why valley-free routing is desirable.
- That OSPF does not provide valley-free routing.
- That BGP provides valley-free routing when spines use same ASN.
- That BGP does not provide valley-free routing when spines use different ASNs.
- That NX-OS by default does not advertise a prefix to a peer where AS path contains the AS of that peer.
I’ll see you in the next post when we dive into BGP path hunting.
Thanks very much bro for what you offer
Thanks!
Thank you!!! Keep it up, please.
Thank you!
What a nice and it is a crystal clear about Valley, Valley-Free routing matter in DC.
Thanks!
Hey Daniel,
Amazing blog as always !! Now we know why we use BGP for underlay instead of OSPF. Your blog posts and even LinkedIn posts are always insightful.
Btw a correction is needed in the summary section about use of same and different ASN for valley free and valley routing.
Thanks! It has been corrected 🙂
Well-explained and clearly documented.
Thanks!
* That BGP provides valley-free routing when spines use different ASNs.
* That BGP does not provide valley-free routing when spines use same ASN.
these 2 points are incorrect, it should be other way around
Damn typo! Thanks, Alex!
What would be the downside of adding a link between the spines so the traffic would not traverse the leaf switches in case of a broken connection? If everything is working the shortest (eBGP) path would be chosen to the destination, with the spine to spine path (iBGP) being used as a backup.
Would adding routed links between the spines be a good design?
Normally, no. There are reasons to do it but generally you don’t want links between two leaves or two spines.
What are those reasons?
Would IS-IS with OverLoad bit set on leaf switches achieve valley-free routing? Is there any downside of doing so? Is IS-IS better than OSPF for underlay in terms of valley-free routing?