I have been playing around with Python lately with the goal of building basic skills in it. I have found that to make good progress what works best for me is:
- Have a project that I find interesting to work on
- Spend a little time every day on the project
The project I decided on was to get the IP addresses that AWS uses for their services, build an access-list based on these prefixes, and then configure a Cisco ASA with that access-list. The final result looks like this:
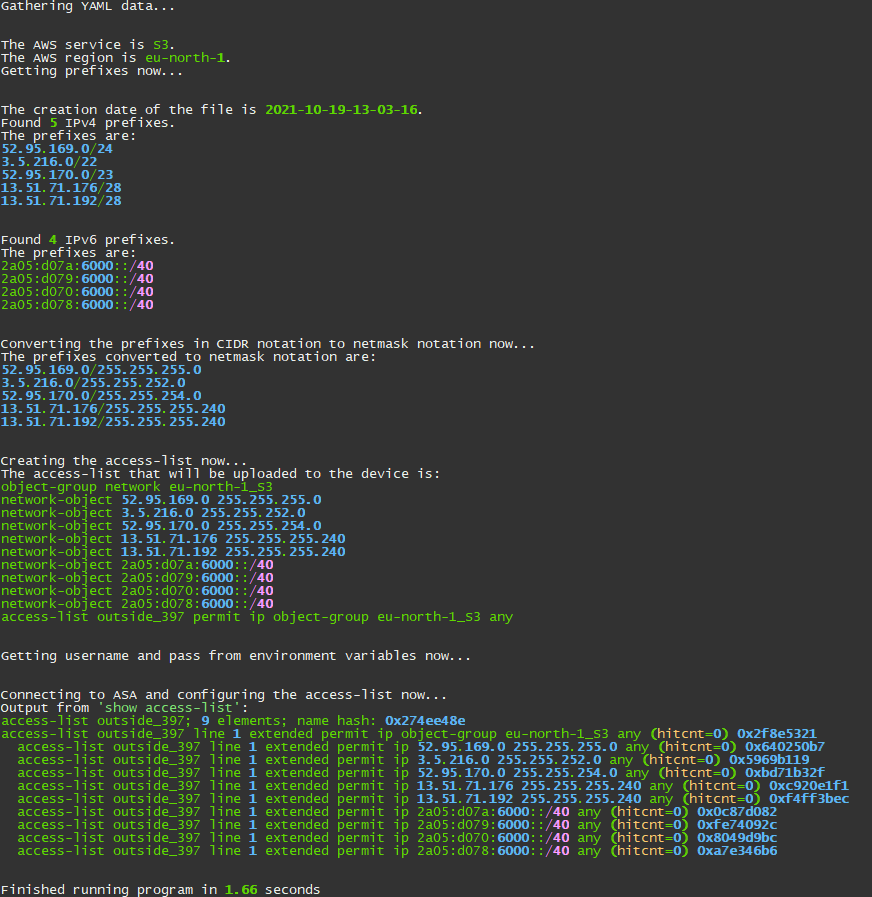
In a series of blog posts, I will cover how I built this script. Keep in mind that my focus was to get a script that works and then improve on it. I have some plans for getting an experienced Python coder to go through the code with me and to work on improvements. Stay tuned for that!
As with any coding project, you need to come up with some general guidelines on how to get data and what is good enough. These are some of the considerations I had:
- I will get the configuration needed from a YAML file rather than a CLI (good enough for now)
- The login and password are stored in environment variables (good enough for now)
- I will leverage modules, builtin or 3rd party, to for example convert IP addresses rather than reinventing the wheel
Providing a CLI and getting the login from a vault are things I’m considering to improve on the project.
Now, for this first post, let’s focus on what I am importing into the script:
import random import yaml import os import requests import ipaddress import time from rich.console import Console from scrapli import Scrapli
I will explain what these modules are and why I use them. I will explain more in detail about them in the upcoming posts showing them being used in my code.
Random – I am using the random module to (obviously) generate a random number. This is needed for the access-list.
YAML – The configuration needed is read from a YAML file using pyYAML. We will go into this in detail in a later post. If you want to learn more about YAML you can go to this post.
OS – The OS module is used to read the environment variables.
Requests – Requests is a very popular HTTP library often used to interact with web sites and APIs.
IP address – The IP address module is very useful for creating IP addresses and converting from netmask to CIDR format and vice versa, getting the number of available IP addresses in a subnet, and so on.
Time – The time module is used to time how long it takes to run the script.
Rich – Rich is an amazing project from Will McGugan that can do pretty printing, colorizing print outputs, formatting beautiful tables, and a lot more.
Scrapli – Scrapli is a great project from Carl Montanari that can be used to interact with network devices. It’s an alternative to for example Netmiko by Kirk byers.
That will be all for this first post! I am keeping them short and sweet. In the next post we’ll be looking at how to pull data from a YAML file.
Daniel,
That’s the way to go! You can’t just teach yourself coding without some practical tasks to solve. A quite interesting little project. Would love to see the source code 🙂
Thanks buddy! I’ll share it with you.
Daniel -great article and blog. I’ve been following you for some time and would like to know how are you able to pull the IPs of other AWS services that are not EC2 and generate a differential report from the previous time it was ran?
I haven’t tried this but it should be doable. To only get prefixes from EC2 you could filter the JSON that they supply. There are probably other options available via API and CLI as well. For diff, I would look into using a module for that. I’m sure there are already solutions for this in Python.
Pingback: Python Script Pulling AWS IP Prefixes – Part 1 - permit-any-any.com