In the previous post, we looked at some of the challenges with L2-based networks. Now let’s start diving into what VXLAN is and what it can provide. First, let’s talk about overlays.
Overlays
Overlays are not new. We have had overlays for many years. The most well known ones are probably GRE and MPLS. In general, overlays are used to create a level of indirection that extends network capabilities. For example, MPLS L3 VPNs provided some of these capabilities to IP networks:
- Segmentation.
- Overlapping IPs.
- Custom topologies.
- Scaling.
- Multihoming.
With overlays, intelligence is often pushed to the edge of the network while intermediate devices can be “dumb”. This can reduce costs as not all devices need the advanced features. How does an overlay work? To create the indirection, the original frame or packet needs to be encapsulated. Depending on the type of overlay, the frame or packet could get encapsulated into another frame or packet. The transport between the overlay nodes is called the underlay. This is the network that transports packets between the nodes. For VXLAN, this is a layer 3 network.
Because overlays encapsulate frames or packets, the size of the frame or packet will increase. To compensate for this, the MTU of the network is often increased from the standard 1500 bytes to something higher such as 1550 bytes, or possibly even jumbo frames where a MTU of 9000 bytes or more is common. Jumbo frames are generally not available on the internet, though.
For the overlay to work, it must also be aware of what hosts are behind which overlay device. There are different mechanisms for this such as:
- Flood and learn.
- Centralized controller such as APIC in ACI.
- EVPN.
Flood and learn is the traditional mechanism used in L2-based networks where a switch learns MAC addresses based on incoming frames. Remember, there is no protocol to exchange MAC addresses between switches. No adjacencies are formed. In SDNs, there is some form of controller such as APIC in ACI or vSmart for Catalyst SD-WAN that can provide information to network devices about hosts/networks in the fabric. EVPN is a BGP-based protocol that can be used to provide information on hosts/networks and where they are located.
The overlay using this information will push the appropriate header to send the frame/packet to the intended destination device and subsequently the destination end host. The host generally belongs to a tenant, be it a VLAN, VRF, or other form of tenancy. The overlay must also take this into consideration and populate the appropriate fields with tenancy taken into consideration.
In addition to unicast traffic, the overlay also needs to support multidestination traffic. This is often referred to as BUM, broadcast, unknown unicast, and multicast. There are two main methods to handle BUM traffic:
- IP multicast.
- Ingress replication (also called head-end replication or unicast mode).
While we generally think of overlays as network devices only, there are also hosts that are capable of running VXLAN. In addition, there are also virtualization platforms such as NSX-T that can be part of an overlay.
The diagram below shows the concept of an underlay:
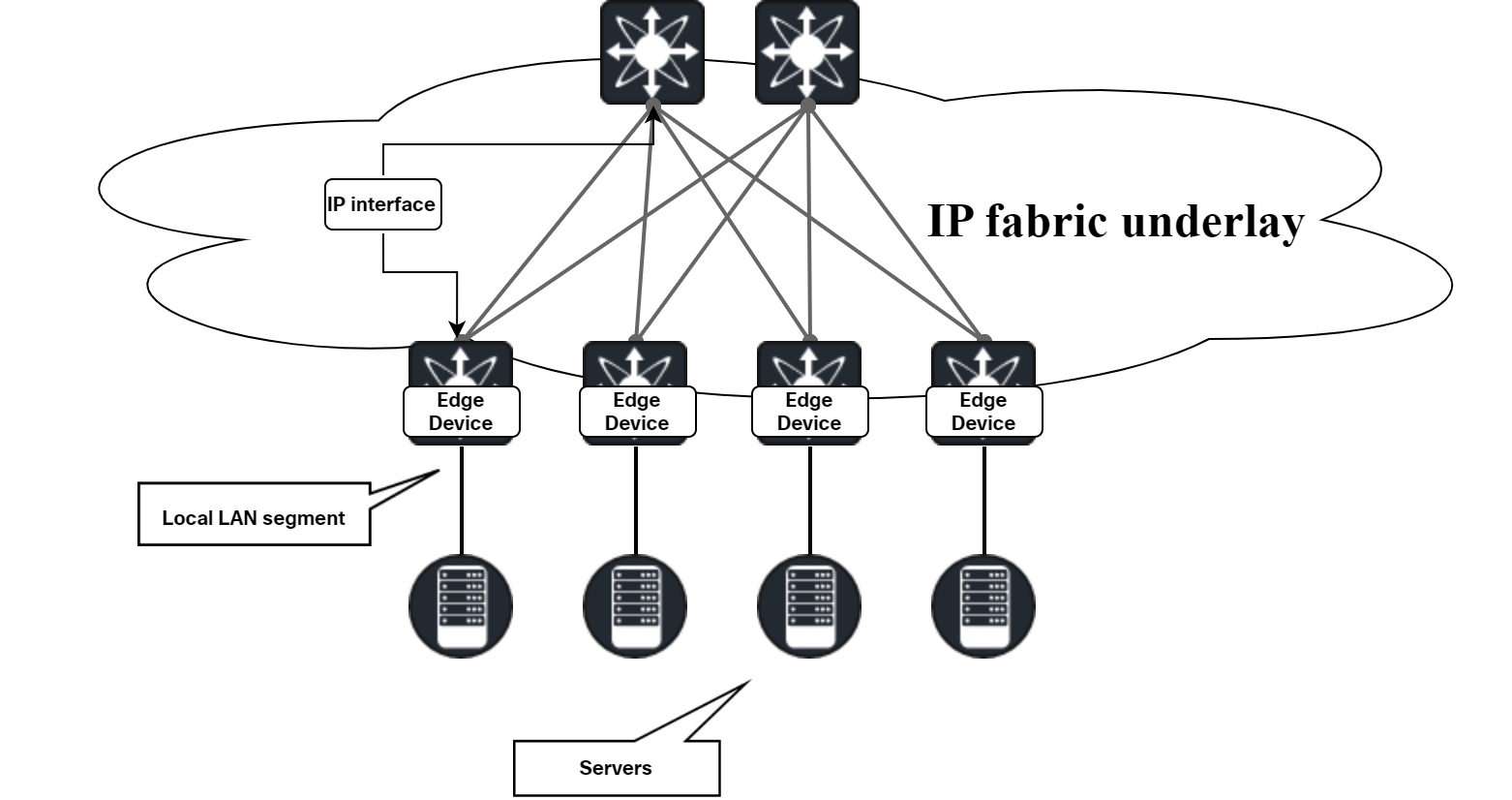
The diagram below shows the concept of the VXLAN overlay:
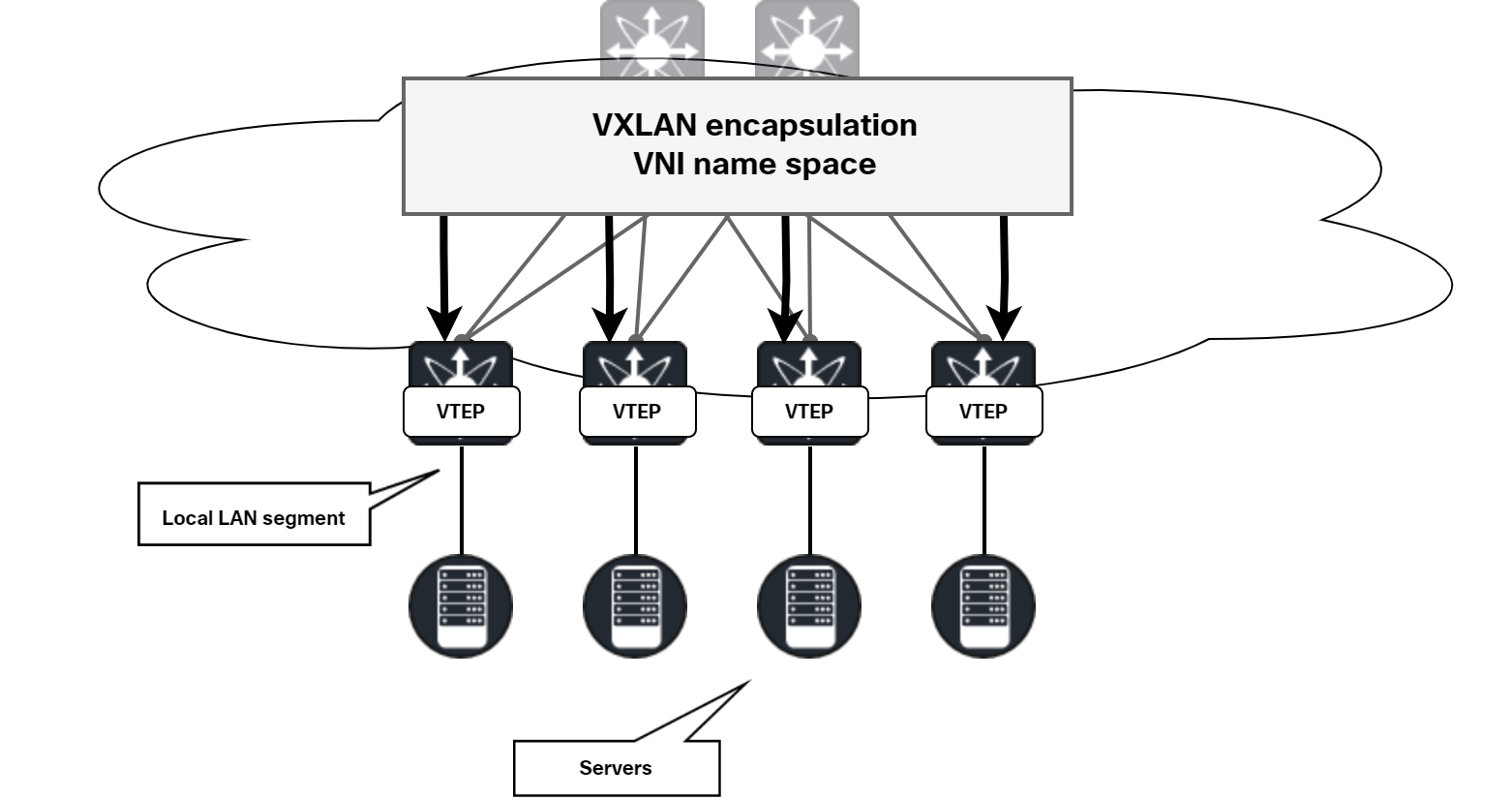
The edge nodes are called VXLAN Tunnel Endpoints (VTEP). To identify the specific service in VXLAN, a VXLAN Network Identifier (VNI) is used.
Introduction to VXLAN
VXLAN is a MAC-over-IP/UDP protocol that extends network IDs from 4096 for VLAN to 16 million for VXLAN. Edge nodes have the VTEP functionality meaning that they push and pop VXLAN headers.
The beauty of VXLAN is that it runs on top of L3 networks while still providing L2 service. This means that the underlay can be a simple L3 network that is not relying on STP for loop prevention. This also means that ECMP can be leveraged to provide multiple paths, load sharing, and better usage of the available links.
As described before, overlays add headers to the original frames/packets. VXLAN encapsulates the frame into a VXLAN/UDP header as can be seen below:
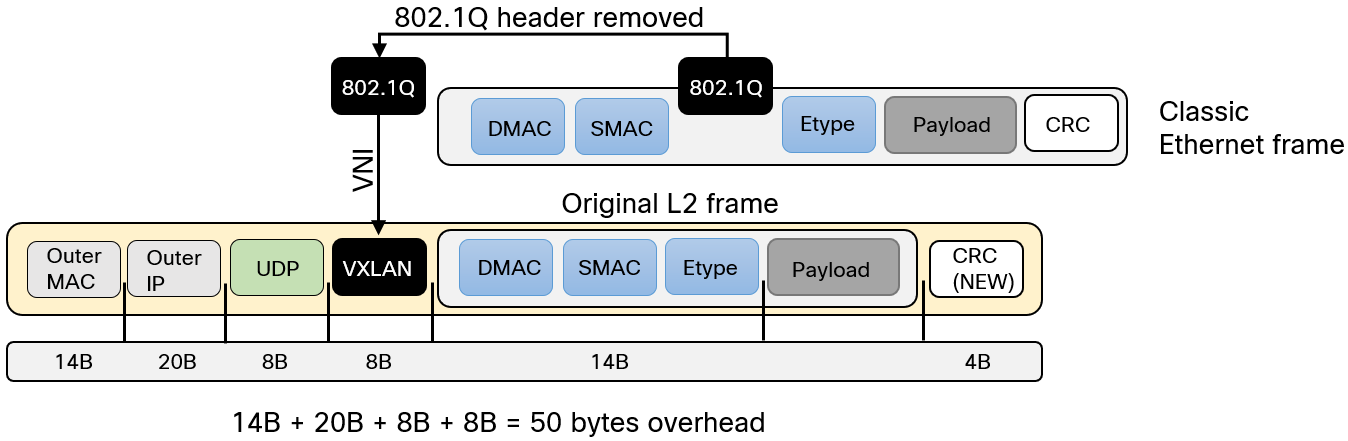
There is a lot to digest here. Let’s break it down:
- VXLAN header is added containing mainly the VNI.
- The 802.1Q header is removed and mapped to a VNI in the VXLAN header.
- The original CRC is discarded and a new one is calculated.
- Because the old CRC is discarded, the new CRC does not add to the overhead.
- UDP header is added with a destination port of 4789. Source port is based on fields of the inner header.
- Adding UDP header provides entropy for load sharing algorithms used in the underlay.
- Outer IP header is set to source IP of source VTEP and destination IP of destination VTEP.
- Outer MAC would consist of source MAC of source VTEP and destination MAC of next-hop to reach destination VTEP.
- VXLAN adds in total 50 bytes of overhead for IPv4 packets.
- Add an additional 4 bytes if 802.1Q is used in the underlay.
- For IPv6, add another 20 bytes due to the larger header.
Underlays and multidestination traffic
The underlay must provide unicast and multidestination delivery of packets. The underlay is built using routing protocols such as OSPF or ISIS although any protocol could be used, such as BGP, to provide the IP connectivity. For multidestination packets, such as BUM mentioned previously, it’s possible to run multicast in the underlay by the use of Protocol Independent Multicast (PIM). Different modes such as Any Source Multicast (ASM), Source Specific Multicast (SSM), and Bidirectional PIM (BIDIR) can be used. A VXLAN VNI is mapped to an IP multicast group. This is done by configuration. The VTEP joins the multicast tree established via PIM. As does all the other VTEPs that are part of the same VNI. The destination IP of the outer header then changes from the destination VTEP IP to the IP of the multicast group.
VXLAN flood and learn
Because VXLAN very often gets paired with EVPN, the standard behavior of flood and learn gets overlooked. Flood and learn is the same type of learning that takes place in a traditional L2 network. The diagram below shows the concept of flood and learn:
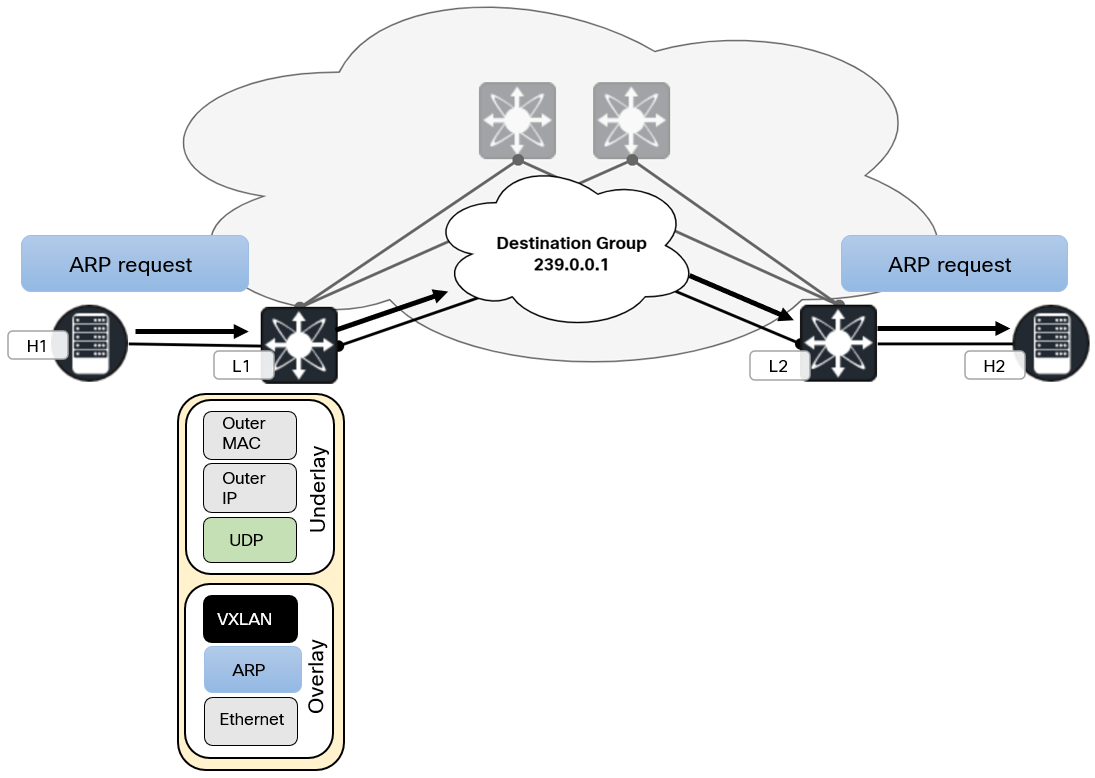
In a flood and learn network, where there has previously been no traffic, the following takes place when the two hosts want to communicate:
- H1 generates ARP request and forwards towards L1.
- L1 learns the MAC of H1.
- L1 performs L2 lookup based on destination MAC and VNI and determines that it is a multidestination frame.
- L1 adds VXLAN header and sends packet to the multicast group 239.0.0.1
- This packet is routed in the underlay and forwarded to L2.
- L2 decapsulates the VXLAN packet as it is part of the same multicast group and has the same VNI configured.
- L2 learns the MAC of H1.
- L2 forwards the ARP request (broadcast frame) to all participants of the VNI, including H2.
- H2 sends an ARP response towards L2.
- L2 learns the MAC of H2 and does a L2 lookup for H1.
- L2 adds VXLAN header and sends packet to L1 directly (no multicast).
L1 learns the MAC of H2. - L1 forwards the ARP response to H1 directly (no broadcast).
With this flood and learn process, multidestination traffic is flooded over VXLAN between VTEPs to learn what host MACs are behind what VTEPs.
Because there are 16 million VNIs, and much fewer multicast groups, VNIs may share the same multicast group. Having a 1:1 mapping between VNIs and multicast groups would require a lot of software and hardware resources. There would be many multicast entries in the underlay. Most deployments may only support 512 or 1024 multicast groups. With not having unique multicast groups, VTEPs may receive traffic for a VNI that is not locally configured. While this is a waste of bandwidth, isolation at network level is still maintained as the VTEP will drop the packet. It performs lookup based on VNI and MAC.
One alternative to multicast is performing ingress replication (also called head-end replication). With ingress replication, every VTEP must be aware of other VTEPs and their membership in VNIs. The source VTEP will then generate x amount of copies of a packet for each VTEP that has membership in the VNI. This removes the need for multicast in the VNI but generates additional traffic compared to multicast.
Using flood and learn in a VXLAN-based network will come with some of the disadvantages of a traditional L2-based network. This is where EVPN comes into play. We will leave that for another post. In the next post in this series we will deep dive into flood and learn behavior.
Great post! Loved the break down on how flood and learn works over vxlan. Looking foward to the next one!
Thanks, Cory!
Very well explained, Daniel! I am waiting for the next post in the series. 🙂
Hello Daniel, You have explained VxLAN intro in a very easy to understand way. Eagerly waiting for next posts on VxLAN.
Awesome posg
Thanks!
Informative and streamlined post, thanks Daniel!
Thanks!
Thank you,
I hope you keep up with such excellent posts!
Very informative and very well written.
I wish you could find some time at the end to describe production scenarios and suggestions.
Thanks!
I’ve been struggling to understand how overlay networks using vxlan work for some time; this post really helped clarify things for me, thank you!
Thanks! Happy to hear that.
Hi Ehsan, great article. I´ve read through it and I´d like to clarify some aspects about the endpoint learning process in ACI.
The APIC controller has no influence or participation in endpoint learning; this is fully performed by the fabric switches. The APIC is a declarative controller that implements only the Management and the Policy planes, while endpoint learning in ACI is a hybrid of Data Plane learning (equal to VXLAN DP/Flood and Learn/Conversational Learning) in the leafs and Control Plane learning via ZMQ/COOP in the spines.
The leafs run the EPM (Endpoint Manager) process that learns local endpoint information (MAC, IP, BD, VRF) and informs the spines about it using the ZMQ (Zero Message Queueing) protocol (CP). Spines update and synchronize their Global Endpoint Tables using COOP. Leafs also learn remote endpoints when they need to talk (conversation).
The endpoints learned by the fabric are simply mapped to MOs (Managed Objects) in the MIT (Management Information Tree) in the APIC to complete the object model.
Another point is about the flood and learn process. Your detailed steps show:
– L1 adds VXLAN header and sends packet to the multicast group 239.0.0.1
– This packet is routed in the underlay and forwarded to L2.
The packet is not exactly routed, but flooded based on a Multidestination Tree in the underlay and reaches not only Leaf 2, but all leafs in the fabric that have joined the same Multicast group 239.0.0.1 IP address (as you correctly explain in the previous paragraph).
Regards,
Luiz
Thanks, Luiz!
Note that this article covers standalone VXLAN fabric. Not ACI.
I just wanted to thank you, Daniel, for explaining VXLAN in such a simple and easy-to-understand way. I just found out that you had a blog where you write articles about networking. I’m planning to start preparing for CCIE Enterprise, and I’d like to know if you could recommend any books or trainers for me to use. I just recertified my NP for the third time and decided to try IE and see how it goes.
Thank you!
That’s great! Ping me on Twitter or LinkedIn and we can chat about it.
Nice and simply explained. 😀
Thanks!